

深度学习加速利器:NVIDIA GTX 970与CUDA技术解密
作为深度学习爱好者亦或是专注于该领域的业内人士,您定对借助GPU实现计算加速有所了解。本文将着重解析利用NVIDIA GTX 970显卡及CUDA技术进行深度学习计算加速的方法,助您提升工作效率。
1. GTX970与CUDA技术简介
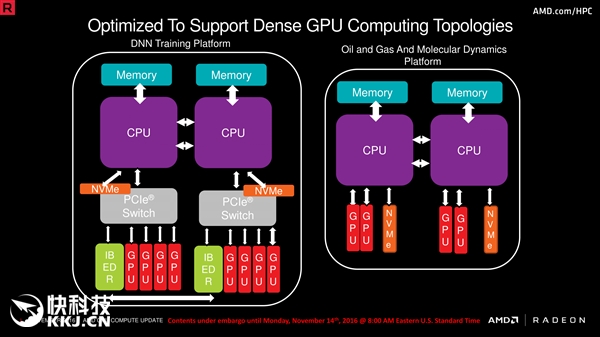
首先,我们对GTX970这一NVIDIA旗下的中档高级显卡以及其搭载的Maxwell架构进行简要概述。此款产品计算实力雄厚、性能卓越,堪称中高端市场的佼佼者。其次,CUDA也是NVIDIA推出的一种强大的并行运算设施及编程模式,可高效运用GPU在通用计算领域的潜在优势,大大提升各类科学计算、图像处理及深度学习的效率。
基于深度学习操作,使用搭载CUDA技术的GTX 970显卡可显著提升训练效率,缩减训练周期。显卡并行运算能力的充分发掘与运用使得复杂神经网络的训练在短期内得以实现,从而为深度学习模型的调整和优化提供更多可能。
2.安装CUDA工具包
为充分发挥GTX 970显卡的CUDA功能,必须先在您个人电脑上成功安装与其配套的CUDA技术工具套装。详情请参阅NVIDIA官网上关于适配GTX970显卡的最新版CUDA的详细指南,按照步骤操作即可顺利完成安装。安装好之后,您也就能正式运用CUDA这一技术来提升深度学习等相关工作的效率了。

3.配置深度学习框架
首先,我们需调整支持CUDA加速的深度学习框架。当前主流的TensorFlow、PyTorch等均能实现对CUDA的兼容,用户仅需在使用时进行简易设置,便可启动GP GPU协同处理能力。届时,配合调整后的框架和CUDA技术,将尽显GTX970显卡在深度学习任务中的杰出性能。

4.优化代码实现
除配置框架之外,通过优化代码,我们亦可提升CUDA的运算效率。举例来说,深度学习模型中的网络构建及激活函数、损失函数的选取以及批量数据的调整均会对GPU运行速度产生积极效果。据此,我们可以充分挖掘GTX970显卡在深度学习应用上的性能潜力。

5.并行计算原理
深入理解并行计算原理对于高效运用GTC970的CUDA加速至关重要。GPU较CPU更适宜并行处理的原因在于其众多的内核和线程,可同时执行多项任务。将大任务细分为多个子任务,在GPU上并行执行这些任务即可实现高速运算,提升运行效力。

6. GPU内存管理
需关注的另一重点在于GPU内存的妥善调配。使用GTX970执行深度学习任务时,由于模型参数及所含数据量庞大,导致训练进程中显存消耗严重。故须对GPU内存进行科学管理,防止出现内存溢出或效率降低的现象。可采用缩小批量规模、释放无用中间变量等策略以实现高效的GPU内存分配。

7.深度学习实践建议
最终,当我们运用GTX 970实施CUDA加速时,有几个关键的注意事项:首要任务是从驱动程序以及CUDA工具包中获取最新的功能及性能优化;其次,应定时清洁显卡的散热装置以保持高效散热;此外,适度的超频亦可进一步提升显卡性能(但是,务必小心处理,以免对设备造成损害)。
经过深入剖析,希望您对GTX970配以CUDA技术实现深度学习任务提速有了更为明确的理解。本文为您提供有力支持,愿您在深度学习领域收获丰硕成果!






